松井FXさんでリピート系が少額から出来るようになったことに対応して、トレーディングビューとRを駆使して最適っぽい解を考えてみるという回です
トレーディングビューからデータを取得する!
今回は月あたりの変動の幅、いわゆる「ボラティリティ」に近い概念と、どのあたりの価格帯で揉み合うのか、などを考えてみたいので、月足と、直近の5分足でデータ要約してみたいと思います。
そこで、まずはデータを取ってくるわけですが、今回もトレーディングビューでデータをとってみましょう。

ローソク足は、さかのぼれるだけさかのぼって、表示できないとこまで行くと、取得可能な全データを取り出せます。データはご自身の見たい通貨を選んでください。今回はこの記事では、USDJPYを使っています。
画面を、さかのぼり切った状態にして、緑矢印のところをクリックし、出てきたところからチャートデータのエクスポートを選択します。
そうすると、日時形式はどうするか聞かれますが、今回は日時は特に使わないので、何でも良いです。エクスポートしましょう。
そうすると、ダウンロードされます。
ブラウザの右上にダウンロード完了!みたいなタブが出る人もいれば、何も出ない人もいると思いますが、その場合は「ダウンロード」というフォルダに収まっていると思います。開いてみましょう。
こちらはエクセルで開いていますが、PCによってはテキストファイルとして開かれると思います。
そしたら、名称を適当なものにして「ドキュメント」に保存します。というのも、FP嶋のRstudioはドキュメントのファイルにアクセスするようになっているためです。Rで使うファイルが、ドキュメント以外のところを参照するような設定になっているなら、そちらのフォルダに移動しましょう。
今回は月足データをFXmon.csv 5分足データをFX5.csvとしています。
Rで解析
Rで以下のようにしてみましょう。
data <- read.csv("FXmon.csv") # データを読み込む
vola <- data$high - data$low # 高値から安値を引く、つまり、月の値幅を計算
avevola <- mean(vola) # 平均値を計算します
varvola <- var(vola) # 分散を計算します
sdvola <- sd(vola) # 標準偏差を計算します
maxvola <- max(vola) # 値幅の最大値を取得します
minvola <- min(vola) # 値幅の最小値を取得します
sumvola <- summary(vola) # データを要約してくれます
histvola <- hist(vola,100,col = "#ff00ff20") #ヒストグラムを書きます。同時にいくつかのデータを格納します
まずは月足のデータを見てみます。
データを読み込むと、データフレームとしてdataに月足データが格納されます。
データフレームは$マークを付けてやると、列ごとにデータを抽出できます。したがって、data$highは、dataという名前のデータフレームからhighと名前の付いた列をベクトルとして取り出します。
ここでは、高値から安値を引いています。つまり、ひと月の最大値から最小値を引くことで、1か月の変化量がわかります。
各変数を呼び出してみましょう

sumvolaの要約値と、各計算結果が同じ(厳密には四捨五入でちょっと違うけど)ですね。
ただ、分散や、偏差はsummary関数ではわかりません。逆に、中央値、第一四分位、第三四分位はsummaryで簡単に出せます。
平均値は全部の値を足して、個数で割った値として、広く知られていますが、中央値、四分位は意外と知られていません。
中央値はデータを順番に並べて、真ん中に来る値。四分位は中央値で分けた上位と、下位の、さらに半分(データを並べた時に1/4、3/4の位置)に来る値です。
平均したら、ひと月で、450pips動くという事ですね。並べてみた時の順位の中央は395pipsの変動があるよっという事。
ちなみに最大でひと月に1500pipsも動くので、リピート系はこの動きに耐えられる必要があります。 一方で、最小値は130pipsなので、利確設定はこれよりも小さいものにした方が良いでしょう。
また、中央値から前後に最小値分動くと、概ね四分位点に来るので、130pipsというのは値幅として目安になるかもしれません。
ただ、気を付けないといけないのは、データを取得した期間で、ドル円の最安値が75.562、最高値が151.946と、pipsの価値が倍位違うという点も忘れてはいけません。
つまり、現在は140円付近なので、MAXに近いので、上方向に引っ張られていると言えます。したがって、最小の値動きは130pips程度ですが、その倍は動くと考えたほうが良いと思われます。
また、この考えをサポートするデータとして、標準偏差が約240pipsである点にも着目しましょう。
データが正規分布する場合、平均値から±標準偏差内にデータの大体6割が集まっているとされています
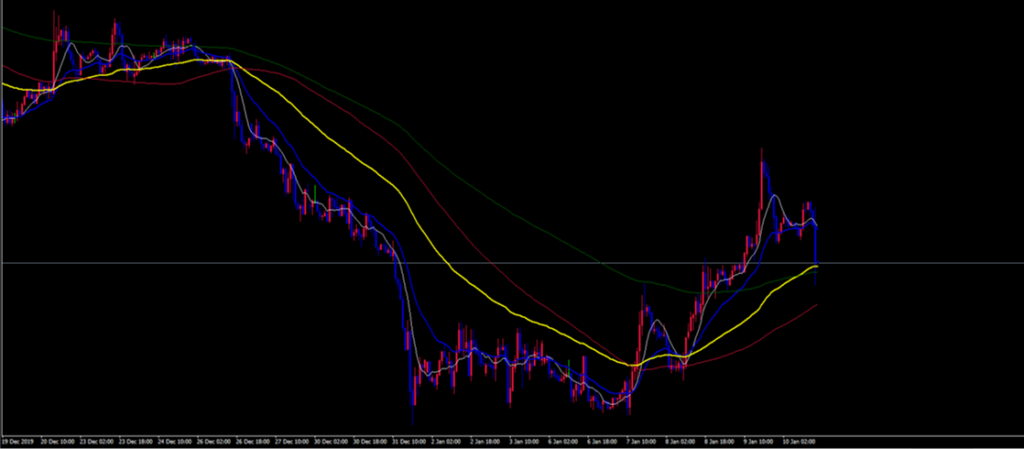
後ほど少し解説しますが、ヒストグラムを簡単に書くのはhist() 以下のような図が出ます。
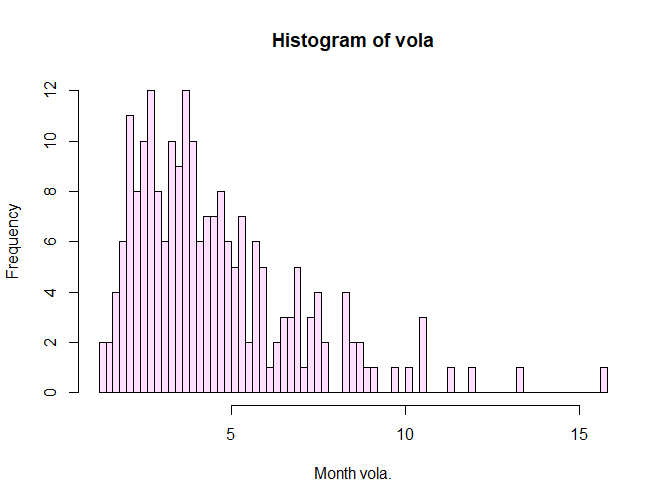
まぁどう見ても正規分布はしていません...
直近の解析もしてみよう!
次に直近の値動きについて見て行ってみましょう。5分足データを使っていて、5月からのデータが取得できました。執筆時点で概ね3か月分という事になります。
data <- read.csv("FX5.csv") # 読み込むデータをかえるだけで再利用!
vola <- data$high - data$low
avevola <- mean(vola)
varvola <- var(vola)
sdvola <- sd(vola)
maxvola <- max(vola)
minvola <- min(vola)
histvola <- hist(vola,100,col = "#ff00ff20",xlab = "5min vola.",xlim = c(0,0.5)) # 最大値の関係で見づらいのでxlimで範囲を指定した
sumvola <- summary(vola)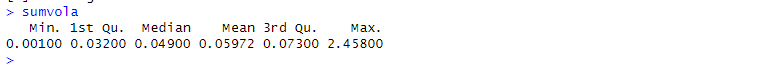
sumvolaしか出していませんが、3~7pips程度動くのが5分足という事になりそうです。
しかし、それにしても最大値、怖いですね…
まぁ指標というか、日銀の政策発表が、あいだにあったからだと思います。
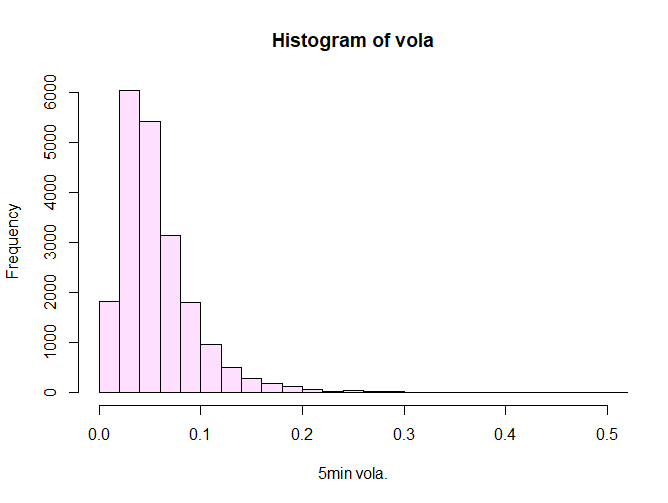
maxの250pipsが入らない様に、制限をかけています。X軸の範囲指定はxlim = c(最小値、最大値)です。 まぁこちらも正規分布はしていませんが、マイナス方向に行かないので仕方ないと言えば仕方ないですね。
次にもみ合う価格帯について考えてみたいと思います。
data <- read.csv("FX5.csv") # 5分足を読み込んでます
High <- data$high # 高値をHighに格納
Low <- data$low # 安値をLowに格納
seqlist <- list() # これから使うseqlistという容器を生成
for (i in 1:length(High)) {
seqlist[[i]] <- round(seq(Low[i], High[i], by = 0.001),3)
} # for文で seqlist内にデータをどんどん格納
h <- unlist(seqlist) #リスト形式をベクトル形式に戻す
hist <- hist(h,5000,col = "#00aaff40",border = NA,main = "Histogram of 5min price",xlab = "price")
#ヒストグラムを書く 境界線はナシにしましたコードについて補足説明をいくつか行います
- list() : Rのリストという形式を作る。中に入れるものは何でも良いという便利設計ですが、使いどころは意外と難しい
- round(): 四捨五入等を行える。業界的には「まるめる」という。roundだから。まるめる対象と、何桁でまるめるかを指定
- for(){}: 繰り返し{}のプログラムを行う。回数は()内のin以降で指定。今回は「1:length(High)」なので、1からHighの長さ(含まれるデータの数)。また、可変数を指定する必要があり、良く使われるのがi,j,k
- length() :()内のデータの長さを数える。行を数えるnrow、列を数えるncolなど、数えたいものによって使い分けが必要。
- seq():指定した範囲内を指定した値で分割してくれる。今回はLow[i]からHigh[i]の範囲をby = 0.001ずつに分割している。指定した範囲のスタートとゴールの大小によってはby=以下を-にする必要がある場合もある。
- unlist() : list要素をすべて取り出してベクトル化
- hist() : データを入れるだけでヒストグラムを書いてくれます。分割する数(細かさ)や色、境界線の有無等、基本的なプロットの指定が出来ます。
今回「リスト」と呼ばれる形式を使用しています。データシートやベクトルをメモ用紙に書いたものと考えたら、リストはメモ用紙をまとめるバインダーのようなもの。
何枚目のメモかを[[x]]で指定します。 さらに、そのページのどこを参照するかを[y]で指定します。
つまり、list内の4つ目でそのデータの5番目のデータを呼び出したいときはlist名[[4]][5]と指定します。
> seqlist[[4]][5]
[1] 136.24今回はデータ数が少ないので、これまでに見てきたc()を使って格納するのでも良いのですが、c()を使うと計算が遅くなる可能性があります。
例えばこんな感じ ↓
a <- 1
seqlist2 <- c()
seqlist2 <- c(seqlist2 , a)
seqlist2
[1] 1このaに入る部分をfor文で変化させて足していくのでも良いのですが、seqlist2を毎回コピペしてその後ろにaを足すという作業なので、データ数が多くなると、だんだんコピペが遅くなり、非常に時間がかかるようになります。したがって、以下のように書き換えると少し早くなります。
a <- 1
seqlist2 <- c()
seqlist2[i] <- a
seqlist2
[1] 1for文になっていませんので、ひとつしか入りませんが、例えば、aがベクトルでn個のデータを持ちi in 1:7のfor文であれば7番目まで格納できます。ベクトルのi番目に直接データを入れています。
ただ、aが2つ以上のデータを持つ場合は工夫が必要で、(i番目なのに、データがi+αになっちゃうので、最初の1つ目のデータしか入らず、残りは上書きされていく)その工夫のひとつがlistの活用です。
for (i in 1:length(High)) {
seqlist[[i]] <- round(seq(Low[i], High[i], by = 0.001),3)
}このように書くと、seqlistのlist内の[[i]]番目に、roundで小数点以下3桁で丸められた、seqでLow[i]からHigh[i]までの区間を、0.001でm個に区切ったものを格納できます。便利。
含まれたデータは長さの異なるベクトルがi個入っていますので、unlistでひとつにまとめます。
h <- unlist(seqlist)これで準備は完了です。
簡単にヒストグラムを書く!
以前はggplotを使って書きましたが、実はヒストグラムは簡単にかけまして… hist()で書けちゃいます。
色々やる分にはggplotの方が良いですし、論文書きたいとかならなおさらggplotが良いですが、ちょっとした解析結果を見たいだけなら、hist()で十分。
また、プログラム慣れしていただくためにも、いろいろ使うほうが良いという事で、今回はhist()つかってます
hist <- hist(h,5000,col = "#00aaff40",border = NA,main = "Histogram of 5min price",xlab = "price")
hist()内でデータ、分割数、色(今回は#RRGGBB透明度で指定) 、境界線を指定しています。また、ラベルや、軸の範囲も指定できます。
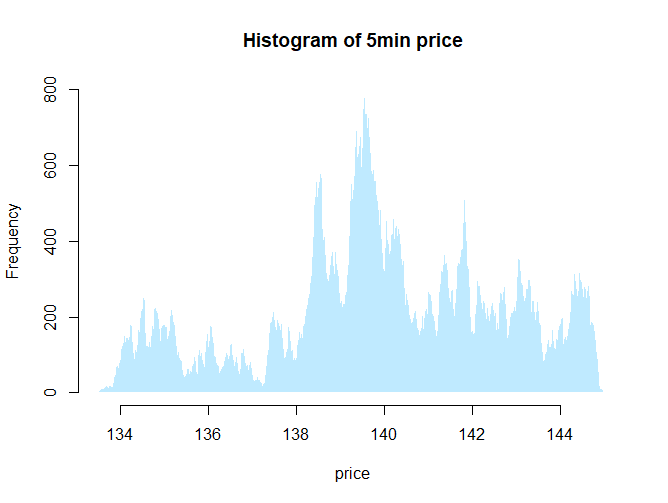
さて、どうでしょうか…これは高安値に挟まれた価格が何回出現したか、つまり、何回その価格帯を通ったか、を示しています。すなわちもみ合う価格帯という事になりますね。
反対に山が低かったり、谷になっているところはスーッと通り過ぎただけという事。つまり、山の両端(谷ってこと)を上限下限としてピーク付近で、もみ合うよ(もみ合ったよ)という事を示しています。
そうみると、この3か月では139~140円の間で非常に多くの取引がなされていたと考えられるでしょう。
また、このヒストグラムを見て、たくさん山があると思うのか、大きい山がひとつと、両側に2,3個山脈があるな~位にとらえるかで戦略が変わっていきますが、ひとつの節目は139~140であることは間違いないでしょう。
リピート設定はどうする?
さて、ここまで見てきたことを振り返りましょう
- 月足は400pips前後動く
- 少なくても130pipsは動く
- 最大で1500pips動く
- 最ももみ合いそうなのは1ドル=139~140円付近
また、ヒストグラムをみると、小さな山でも20pipsの値幅がありそうです。
今回はリピート用にドル円の分析をRで行ってみました。
これをもとに、松井FXのリピートショート設定を考えてみようと思います。
おすすめFXアイテム
過去検証や分析はMT4かFT4、Trading viewがおすすめです。
無料が良い人はMT4で、MT4を使わせてくれる口座を使用すると良いです。おすすめはFXTF
チャート分析に毎月課金してもいいよって人はTrading viewがおすすめです。無料もあります